What's Been Done
Writing a quick update. TLDR; I’ve reviewed two new studies, Cepeda (2006) & Mawson (2025). But my pace should pick up from here.
Over the last couple months I’ve only reviewed two more meta-analyses for the database. Of course, I have a day job, kids, and since I love learning and I practice what I preach, I carve out time to study as well (lately, math refreshing and machine learning engineering). But I’m not satisfied with my progress here at Pavlonic.
Building Tools for Efficiency
Over the last month, it hit me how large of a project I’ve created for myself — even more so given my stubborn ideals about how I sort the data, present it, and refusal to use AI for things that others wouldn’t hesitate to… I will not contribute to the AI sloppification of the internet.
Therefore, I’ve decided to build out more automation tools for myself. Some do use AI, some don’t — but, it’s been a lot of fun and it’s suprisingly effective.
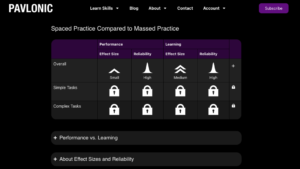
It took me about 6 hours to review the Cepeda study and enter it in the database, but after building one tool, it just took me just 2 hours to review Mawson. It allows me to avoid tedious stuff, and focus on looking at the article myself.
And there are more parts of the process I can automate — so I’m going to take a little more time to build those out now. My goal is to get the process down to 1 hour per study. This means I can very quickly review (given my education, I should be able to understand >95% of an article in 30 min or so), use tools to quickly populate the database, and then spend the rest of the time checking over the data, and writing a quick summary. Once I have ~5 studies per major topic (e.g., spaced practice) for 5 such topics, then the fun begins: creating frameworks that you can use for whatever you’re trying to learn to build a study program that helps you learn as much as possible, as quickly as possible. And perhaps some tools that automate that build-out for you. I really want to get to that stuff as soon as possible, because I can continue to strengthen the database in parallel.
I’m so excited to get there… but again, no AI slop — it has to be grounded in the science, and I have to have reviewed the studies myself.
Onward
I may write a blog post about my experiences using AI so far. It’s absolutely incredible — but where it falls down is exactly where I need precision in this project. Sam Altman keeps saying “PhD level” but I don’t think he really knows what that means. If you’re interested in hot takes like that, let me know.
Back to work!